Porque utilizar o aggregation framework do MongoDB ?
Atualmente estou trabalhando com Java/Groovy, numa plataforma toda feita em microsserviços. Notei um comportamento bem esquisito, no NewRelic em um endpoint específico da API de carrinho.
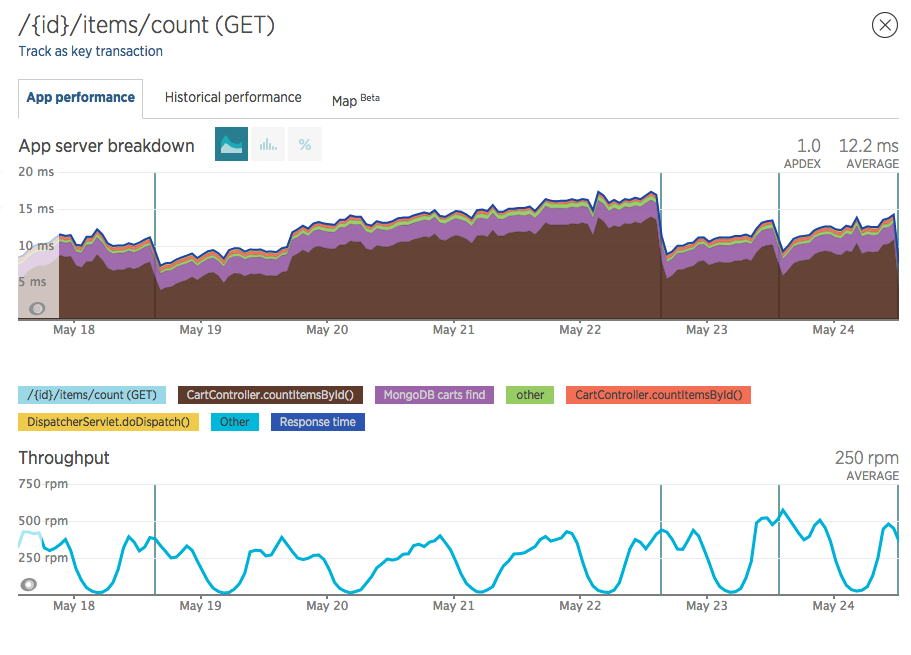
Cada marcação vertical indica que um deploy foi feito.
Note que um pouco antes da marcação de 19 de Maio, o tempo médio da função CartController.countItemsById() (marcação marrom no gráfico), que é puramente código Java estava próximo dos 5 milissegundos, e depois foi subindo, subindo até quase 15 milissegundos, onde um novo deploy foi feito e o tempo baixou.
Ou seja, logo após um deploy o tempo de resposta desse endpoint /{cartId}/count/items cai, subindo gradativamente até um novo deploy.
O service que esse controller chama é este abaixo:
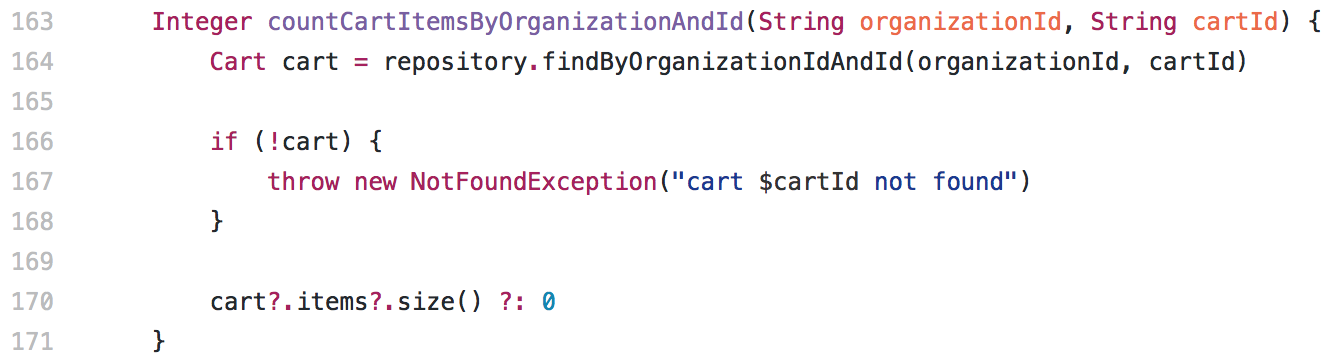
Muito simples e nada aparentemente explica o leak de tempo de resposta, convém notar que não observei esse comportamento no gráfico de memória, apenas no tempo de resposta desse endpoint em específico.
Bom, mas qual problema eu vi no trecho acima? O fato de carregar todo o objeto para apenas contar quantos itens tem dentro de uma propriedade array dele via Java. Essa API de carrinho salva os carrinhos no MongoDB, nessa estrutura:

Viu o array ali em items? o endpoint que estou falando nesse post tem que devolver o número 3 para esse carrinho em questão, e só isso.
Logo, refiz o método do service para usar um novo repository que em vez de devolver todo um Cart (objeto do print acima), devolve apenas um CartCount:
package br.com.blz.checkout.domain
class CartCount {
String id
Integer total
}
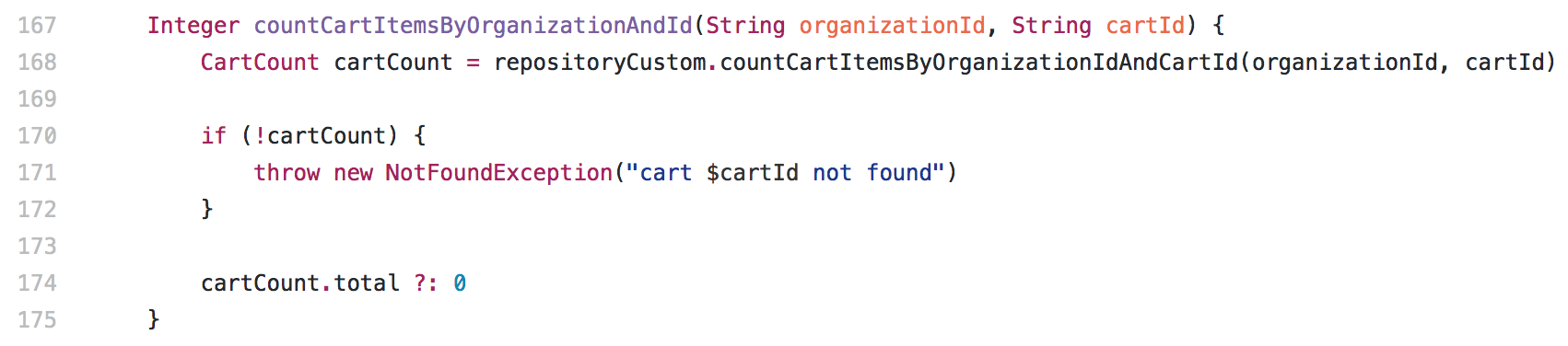
O aggregation inteligente para contar o número de items é este:
[
{ "$match": { "_id": ?, "organization": { "id": ? } },
{ "$project": { "_id": 1, "total": { "$size": "$items" } } }
]
Que escrito em Java fica assim:
package br.com.blz.checkout.repository
import br.com.blz.checkout.domain.Cart
import br.com.blz.checkout.domain.CartCount
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.data.mongodb.core.MongoTemplate
import org.springframework.data.mongodb.core.aggregation.Aggregation
import org.springframework.data.mongodb.core.aggregation.MatchOperation
import org.springframework.data.mongodb.core.aggregation.ProjectionOperation
import org.springframework.data.mongodb.core.query.Criteria
import org.springframework.stereotype.Repository
@Repository
class CartRepositoryCustom {
private final MongoTemplate mongoTemplate;
@Autowired
public CartRepositoryCustom(MongoTemplate mongoTemplate) {
this.mongoTemplate = mongoTemplate;
}
public CartCount countCartItemsByOrganizationIdAndCartId(String organizationId, String cartId) {
MatchOperation matchOperation = Aggregation.match(
Criteria.where("organization.id")
.is(organizationId)
.andOperator(Criteria.where("id").is(cartId))
);
ProjectionOperation projectionOperation = Aggregation.project('id').and('items').size().as('total');
def results = mongoTemplate.aggregate(Aggregation.newAggregation(
matchOperation,
projectionOperation
), Cart.class, CartCount.class).getMappedResults()
results.size() ? results.get(0) : null;
}
}
Resultando no seguinte diff:
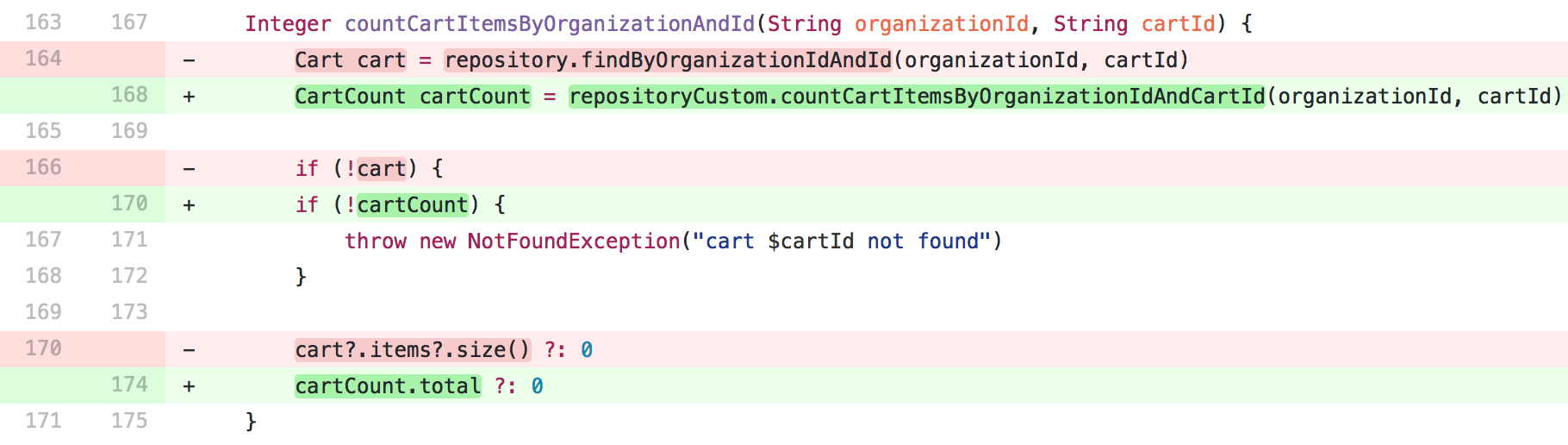
E neste ganho de performance:
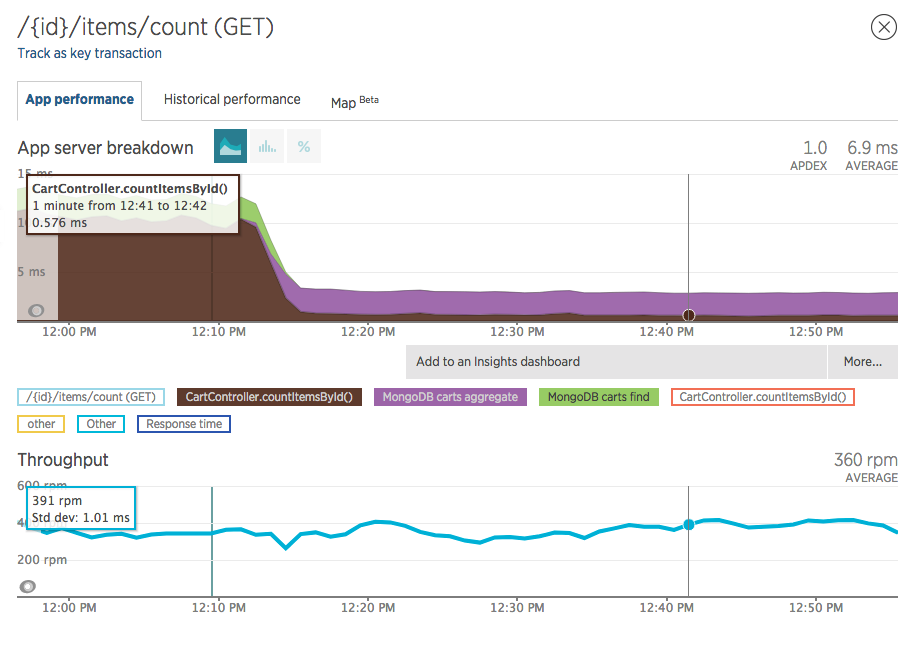
Baixando o tempo no Java de 10ms para 0.6ms (que posteriormente foi para 0.4ms por conta de otimizações internas da JVM), o que não parece “tanto”, mas lembre-se que estamos olhando para a média daquele endpoint, e que obviamente havia algo errado ali.
E mais importante: não voltou a subir, se mantém constante abaixo dos 0.6~0.4ms.
E como troquei um .find() por um .aggregate(), convém observar se houve algum impacto no mongodb, e ele foi nulo, tendo o mesmo tempo de resposta:
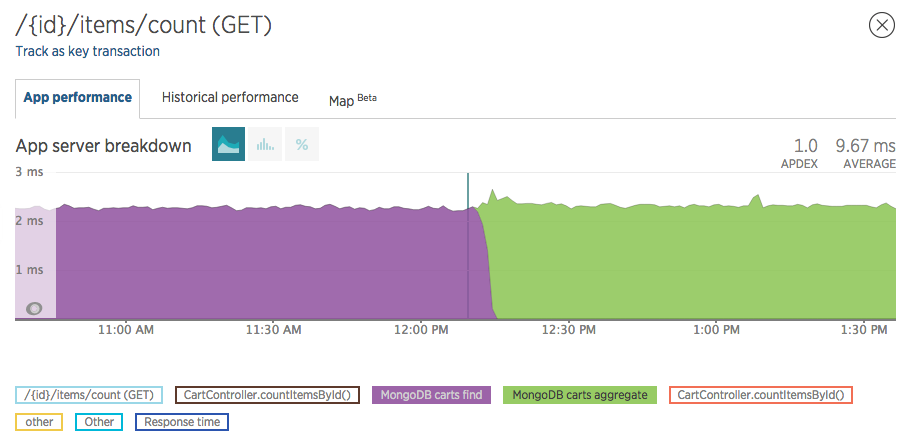
Em torno de 2.3ms, tanto para o .find() quanto para o .aggregate().
O que eu concluo disso é: corrija o que você está enchergando.
Ainda não sei porque o tempo de resposta aumentava ao passar do tempo, mas eu sabia que retornar um objeto gigante, deixar o Java fazer o unmarshall de todas as propriedades, sub-objetos e arrays era um problema, então deleguei o count para o banco de dados.
E com isso melhorei a performance (nada significativo, pois já era muito baixo), e resolvi o aparente leak de tempo de resposta.